publications
(*) denotes equal contribution
2025
- AAAI
 Channel Merging: Preserving Specialization for Merged ExpertsMingyang Zhang, Jing Liu, Ganggui Ding, and 3 more authors2025
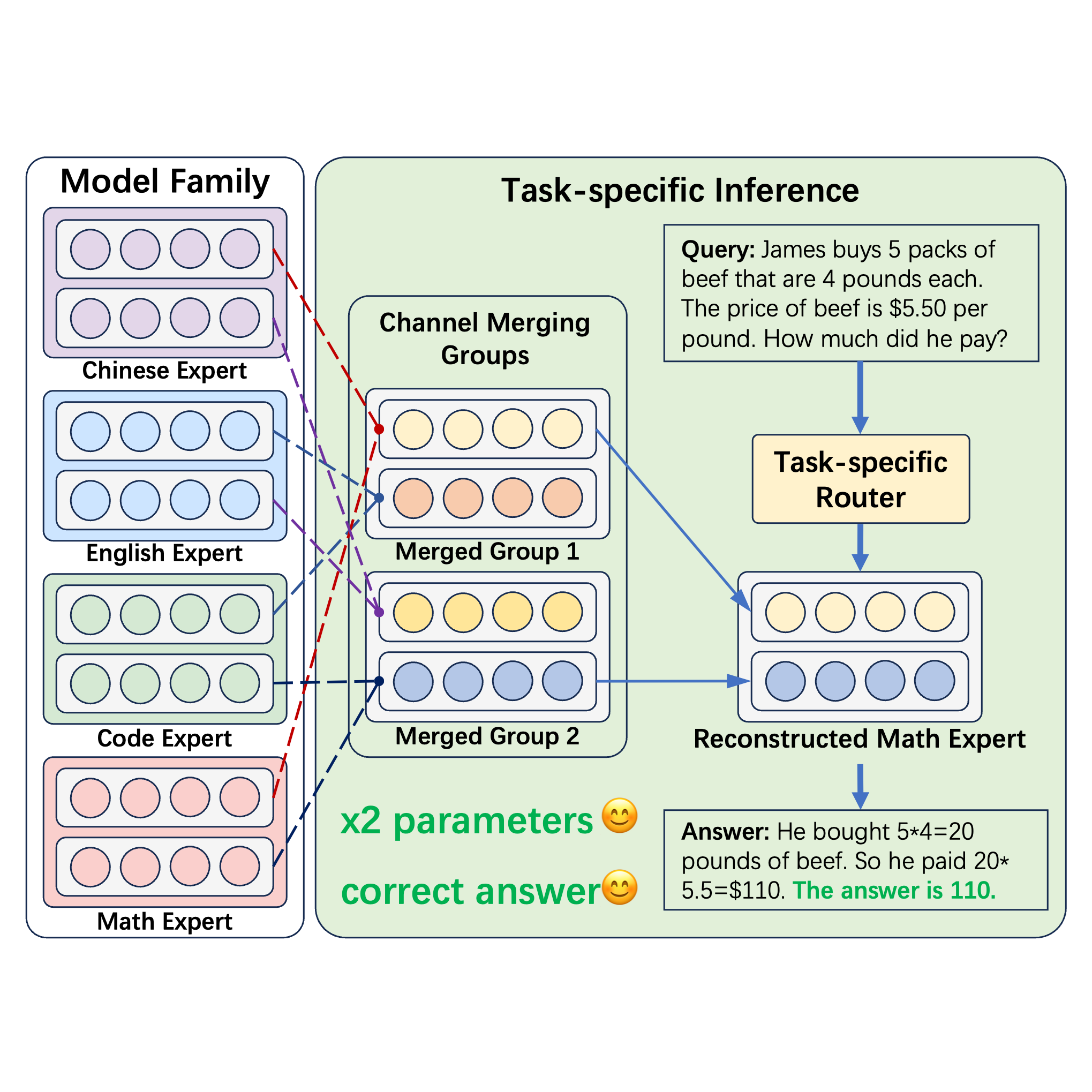
Channel Merging: Preserving Specialization for Merged ExpertsMingyang Zhang, Jing Liu, Ganggui Ding, and 3 more authors2025Lately, the practice of utilizing task-specific fine-tuning has been implemented to improve the performance of large language models (LLM) in subsequent tasks. Through the integration of diverse LLMs, the overall competency of LLMs is significantly boosted. Nevertheless, traditional ensemble methods are notably memory-intensive, necessitating the simultaneous loading of all specialized models into GPU memory. To address the inefficiency, model merging strategies have emerged, merging all LLMs into one model to reduce the memory footprint during inference. Despite these advances, model merging often leads to parameter conflicts and performance decline as the number of experts increases. Previous methods to mitigate these conflicts include post-pruning and partial merging. However, both approaches have limitations, particularly in terms of performance and storage efficiency when merged experts increase. To address these challenges, we introduce Channel Merging, a novel strategy designed to minimize parameter conflicts while enhancing storage efficiency. This method initially clusters and merges channel parameters based on their similarity to form several groups offline. By ensuring that only highly similar parameters are merged within each group, it significantly reduces parameter conflicts. During inference, we can instantly look up the expert parameters from the merged groups, preserving specialized knowledge. Our experiments demonstrate that Channel Merging consistently delivers high performance, matching unmerged models in tasks like English and Chinese reasoning, mathematical reasoning, and code generation. Moreover, it obtains results comparable to model ensemble with just 53% parameters when used with a task-specific router.

2024
- ICLR
 Object-aware Inversion and Reassembly for Image EditingZhen Yang, Ganggui Ding, Wen Wang, and 3 more authors2024
Object-aware Inversion and Reassembly for Image EditingZhen Yang, Ganggui Ding, Wen Wang, and 3 more authors2024Diffusion-based image editing methods have achieved remarkable advances in text-driven image editing. The editing task aims to convert an input image with the original text prompt into the desired image that is well-aligned with the target text prompt. By comparing the original and target prompts, we can obtain numerous editing pairs, each comprising an object and its corresponding editing target. To allow editability while maintaining fidelity to the input image, existing editing methods typically involve a fixed number of inversion steps that project the whole input image to its noisier latent representation, followed by a denoising process guided by the target prompt. However, we find that the optimal number of inversion steps for achieving ideal editing results varies significantly among different editing pairs, owing to varying editing difficulties. Therefore, the current literature, which relies on a fixed number of inversion steps, produces sub-optimal generation quality, especially when handling multiple editing pairs in a natural image. To this end, we propose a new image editing paradigm, dubbed Object-aware Inversion and Reassembly (OIR), to enable object-level fine-grained editing. Specifically, we design a new search metric, which determines the optimal inversion steps for each editing pair, by jointly considering the editability of the target and the fidelity of the non-editing region. We use our search metric to find the optimal inversion step for each editing pair when editing an image. We then edit these editing pairs separately to avoid concept mismatch. Subsequently, we propose an additional reassembly step to seamlessly integrate the respective editing results and the non-editing region to obtain the final edited image. To systematically evaluate the effectiveness of our method, we collect two datasets called OIRBench for benchmarking single- and multi-object editing, respectively. Experiments demonstrate that our method achieves superior performance in editing object shapes, colors, materials, categories, etc., especially in multi-object editing scenarios.
- CVPR
 FreeCustom: Tuning-Free Customized Image Generation for Multi-Concept CompositionGanggui Ding, Canyu Zhao, Wen Wang, and 4 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
FreeCustom: Tuning-Free Customized Image Generation for Multi-Concept CompositionGanggui Ding, Canyu Zhao, Wen Wang, and 4 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024Benefiting from large-scale pre-trained text-to-image (T2I) generative models, impressive progress has been achieved in customized image generation, which aims to generate user-specified concepts.Existing approaches have extensively focused on single-concept customization and still encounter challenges when it comes to complex scenarios that involve combining multiple concepts. These approaches often require retraining/fine-tuning using a few images, leading to time-consuming training processes and impeding their swift implementation. Furthermore, the reliance on multiple images to represent a singular concept increases the difficulty of customization. To this end, we propose FreeCustom, a novel tuning-free method to generate customized images of multi-concept composition based on reference concepts, using only one image per concept as input. Specifically, we introduce a new multi-reference self-attention (MRSA) mechanism and a weighted mask strategy that enables the generated image to access and focus more on the reference concepts. In addition, MRSA leverages our key finding that input concepts are better preserved when providing images with context interactions. Experiments show that our method’s produced images are consistent with the given concepts and better aligned with the input text. Our method outperforms or performs on par with other training-based methods in terms of multi-concept composition and single-concept customization, but is simpler.

